Kubernetes has become a market leader in container orchestration tools. According to the 2019 CNCF survey, “78% of respondents are using Kubernetes in production, a huge jump from 58% last year”
While containers have become the norm for deploying applications, kubernetes has become the norm for container management.
DoS in Kubernetes cluster
Consider a Kubernetes cluster with 3 worker nodes having a memory of 10GB each. Suppose the developers end up deploying some pods by mistake which consumes almost all the cpu and memory available in the node. Hence causing resource contention in the others application pods which serves traffic from consumers. This could also be caused when hackers inject high resource consuming pods intentionally into the system.
To understand this situation better, assume a node having 10GB of allocatable memory for containers and there are 5 application pods sharing the available memory. Each application pod on an average consumes 1GB of memory which makes the node to run at 50% to 60% memory utilization. Now deploying a pod that consumes 10GB of memory in the same node will cause noisy neighbor problem. This results in resource contention in other application pods which in turn either increase the latency of those services or in the worse case make the services go unavailable.
This might also happen when the developer commits a mistake in the code which leaks the memory and increase the memory usage steadily.

Effective Resource Management in Kubernetes
This is the reason why developers should be more conscious of the resources required for the services that they develop and configure the minimum required memory and cpu while deploying it in the Kubernetes cluster. Resource requests can be configured accordingly to schedule the pods in the node which guarantees the minimum resource.
For example, if a service requires 2 cpu and 3GB of memory at minimum, then in the pod specification configure the resource request as follows:
apiVersion: v1
kind: Pod
metadata:
name: demo-service
namespace: demo
spec:
containers:
- name: demo-container
image: demo-service-image
resources:
requests:
cpu: "2"
memory: "3G"
It is also important that the developers should also configure the maximum resources that their service could consume. This helps in avoiding noisy neighbor problem in other service pods.
Let’s say the same demo-service should not consume more than 4 cpu and 5 GB of memory. In that case add the resource limit to the above pod specification.
apiVersion: v1
kind: Pod
metadata:
name: demo-service
namespace: demo
spec:
containers:
- name: demo-container
image: demo-service-image
resources:
requests:
cpu: "2"
memory: "3G"
limits:
cpu: "4"
memory: "5G"
It is strongly recommended to configure the resource requests and limits in the pods deployed in the Kubernetes cluster as per the service needs.
Having said that, just to be on the safer side, we need some policy to be added in the Kubernetes cluster to ensure the pods do not over utilize the resource causing noisy neighbor problem and hence save the apps deployed in cluster from Denial of Service.
Save your Kubernetes cluster from DoS
One solution to the above problem is setting up some kind of a quota on the resources that will be configured as requests and limits in pods. This is to ensure that no one over configures the resource requests and limits and hence avoid the over utilization of resources in the node (beyond some threshold).
Kubernetes provides ResourceQuota to achieve this as it injects an admission controller in validating phase. Most of the kubernetes distribution supports ResourceQuota by default. Even otherwise, it can be enabled by adding ResourceQuota in --enable-admission-plugins flag to kube-apiserver.
kube-apiserver --enable-admission-plugins=ResourceQuota,..
After enabling the ResourceQuota admission plugin, add the quota for each namespace as per need. For example, to allocate only 10GB of memory that deploy their services in a namespace, create a resource quota as:
apiVersion: v1
kind: ResourceQuota
metadata:
name: demo-resourcequota
spec:
hard:
limits.memory: 10G
This resource quota ensures that the sum of memory in resource limits of all pods does not exceed 10GB of memory. Any create or modify request will be validated by the ResourceQuota admission controller in the validating phase. In case of non compliance of the existing ResourceQuota, the request will be rejected.
Now deploy the pod with memory limit of 2GB as follows:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
resources:
limits:
memory: 2G
And by running kubectl describe resourcequota demo-resourcequota, see that 2GB memory limit is used out of configured quota.

When another pod having memory limit of 9GB is deployed, it will fail as it will exceed the quota of 10GB.
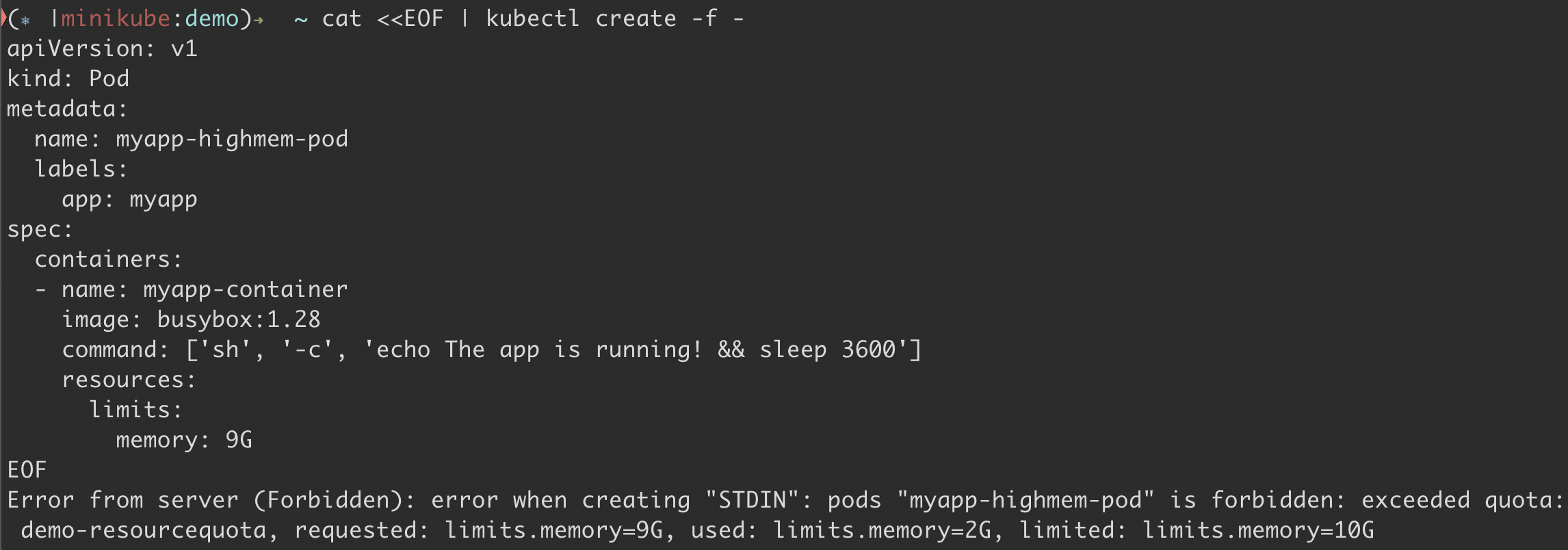
Cluster administrators should configure the values in ResourceQuota so that it does not overutilize the nodes.
In kubernetes cluster, mentioning resource requests and limits in the pod spec is not mandatory and if its not mentioned, it means no limit for resources to be consumed by pod. It can consume resources as much as available in the node. Hence it is not recommended to skip the resource requests and limits in pod spec.
Having ResourceQuota, any pod creation or updation will be rejected if the request or limit of resources that is required by resource quota is missing. For example, the above resource quota will not allow creation or updation of pods that does not have resource limit for memory configured.
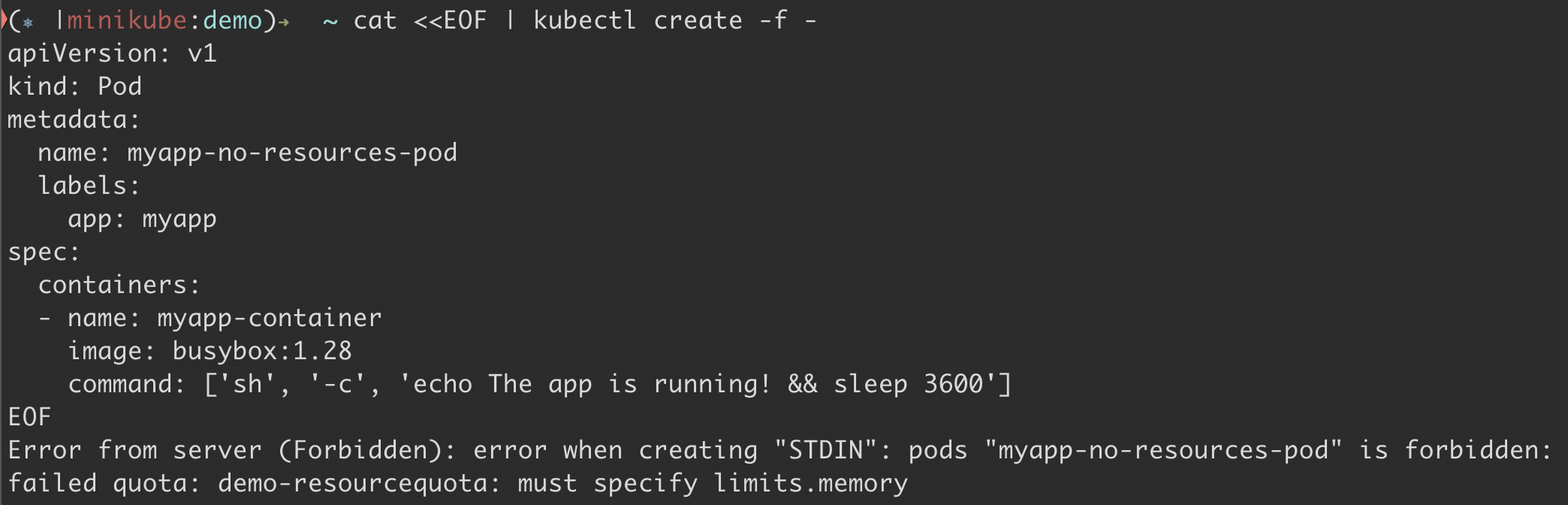
Simply to ensure that all the pods have some default resource request or limit, we can create LimitRanger in the namespace.
LimitRanger is also an admission controller which will be involved in the mutating phase. If any of the pod spec does not have resource requests or limits, it will add the resource request and limit as mentioned in the LimitRanger of same namespace.
Create a LimitRanger in a namespace as follows:
apiVersion: v1
kind: LimitRange
metadata:
name: default-requests-limits
namespace: demo
spec:
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 500Mi
type: Container
And then apply the pod without resource requests and limits in the same namespace as follows:
apiVersion: v1
kind: Pod
metadata:
name: myapp-no-resources-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
Now, get the yaml of the above pod that is running in the K8s cluster. Resource request and limits that is mentioned in the LimitRanger default-requests-limits got added to .spec.resources.
...
spec:
containers:
- command:
- sh
- -c
- echo The app is running! && sleep 3600
image: busybox:1.28
imagePullPolicy: IfNotPresent
name: myapp-container
resources:
limits:
memory: 1G
requests:
memory: 500Mi
...
Once again run kubectl describe resourcequota demo-resourcequota and see that 3GB memory limit is used out of configured quota.

Conclusion
Thus, configuring ResourceQuota and LimitRanger based on requirements, all the applications in the Kubernetes cluster can be saved from noisy neighbor problem and Denial of Service