Throughout my six years of experience working with various K8s clusters across different environments, I’ve noticed a tendency to overlook Inter-AZ data transfer, resulting in significant expenses.
InterAZ (Inter-Availability Zone) data transfer costs within AWS EKS pertain to charges associated with transferring data between availability zones within the same AWS region. These costs fluctuate depending on the volume of data transferred and the region in which the EKS cluster is deployed.
Understanding and managing InterAZ data transfer costs in EKS is crucial for optimizing the overall cost efficiency of running Kubernetes workloads in AWS while ensuring high availability and reliability across availability zones
Inter AZ Data Transfer cost in AWS, GCP and Azure: $0.01 per GB
Hidden Cost of High Availability
Striving for High Availability often involves deploying applications in EKS clusters across multiple availability zones within a region, inadvertently leading to increased data transfer between these zones and subsequent charges.
To illustrate, consider two applications, X and Y, operating in different zones. When X connects to Y across zones, it contributes to InterAZ data transfer.
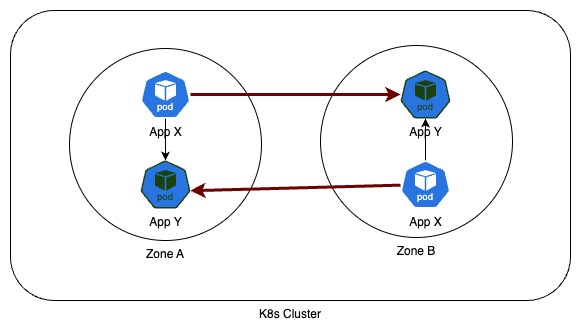
In AWS, data transferred between Availability Zones within the same region falls under the UsageType of Region-DataTransfer-Regional-Bytes. For instance, the USE2-DataTransfer-Regional-Bytes UsageType specifies charges for data transfer between Availability Zones in the US East (Ohio) Region.
Regarding billing, both inbound and outbound traffic for a specific resource incur charges for data transfers within an AWS Region, resulting in two separate line items of DataTransfer-Regional-Bytes for each data transfer corresponding to each metered resource.
Cost-Effective Strategy
Minimising inter-Availability Zone (interAZ) data transfer is crucial while maintaining high availability.
In the provided scenario, it’s advisable to limit App X’s connectivity to App Y which operates in a different zone. This measure not only decreases interAZ data transfer costs but also enhances network performance by connecting to pods situated within the same zone. Kubernetes’ Topology Aware Routing provides a solution to address this concern.
Topology Aware Routing adjusts routing behavior to prefer keeping traffic in the zone it originated from. In some cases this can help reduce costs or improve network performance
Enable Topology Aware Routing for Service Y by setting the service.kubernetes.io/topology-mode annotation to Auto. Endpoint slice controller will add hints to endpoints as follows and then kube-proxy will filter the endpoints based on these hints to route the traffic to a service.
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-hints
labels:
kubernetes.io/service-name: example-svc
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
zone: zone-a
hints:
forZones:
- name: "zone-a"
But Topology Aware Routing works well when there are a minimum of 3 endpoints in each zone. We can use pod topology spread to distribute pods in all 3 zones
topologySpreadConstraints:
- labelSelector:
matchLabels:
app.kubernetes.io/app: Y
matchLabelKeys:
- pod-template-hash
maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
Pod topology constraints are considered only during scheduling of pods. If it is not strict(whenUnsatisfiable: ScheduleAnyway), there are a lot of chances for ignoring this constraint due to node availability. And during rolling update, while scheduling a new pod, it also considers old version pods which will be terminated in next steps. Finally It results in skewed distribution of new version pods.
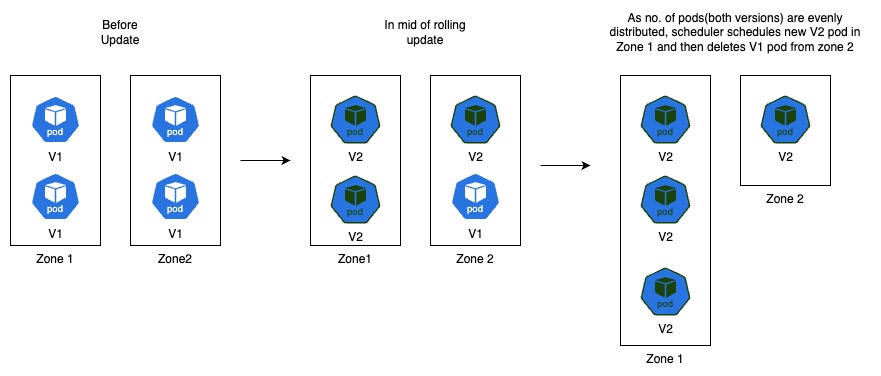
Hence, whenUnsatisfiable: DoNotSchedule and matchLabelKeys: pod-template-hash are mandatory to achieve even distribution of pods consistently.
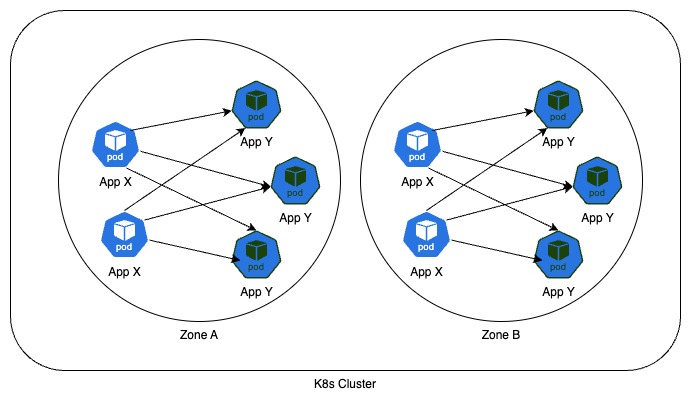
Limitation of Topology Aware Routing
Even after running 3 pods in each zone always, topology aware routing might get disabled when load in a zone is high compared to other zones. This is indicated by the Kubernetes event thrown by the endpoint slice controller. It fails to allocate 9 endpoints to 3 zones without exceeding the overload threshold. It happens when there are lot of CPU in a zone. And it gets enabled automatically once the CPUs in zone is back to the state which does not cross the overload threshold.
TopologyAwareHintsDisabled: Unable to allocate minimum required endpoints to each zone without exceeding overload threshold (9 endpoints, 3 zones), addressType: IPv4
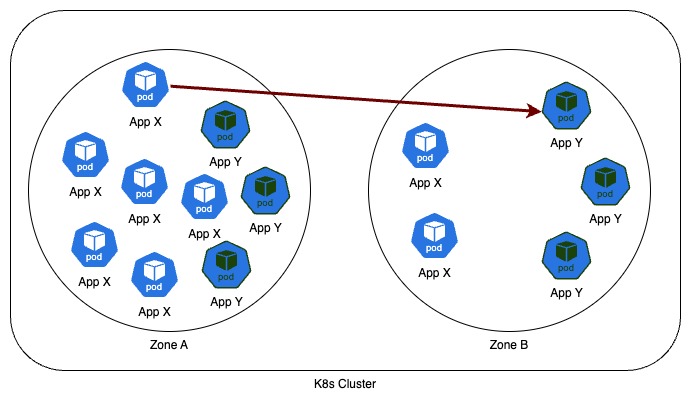
For now, the only way to solve this permanently is to ensure CPUs in all zones are also balanced. But it is challenging as we have some apps that run only in fewer zones.
Better solution
We need more control on the traffic routing behavior irrespective of CPUs in each zone.
Kubernetes’ team proposed an enhancement to satisfy this requirement. And it introduced a new field “trafficDistribution” to offer greater control over traffic distribution to Service endpoints. This new alpha feature is available in K8s version 1.30 which was released this week on April 17, 2024
Now, We can set .spec.trafficDistribution: PreferClose in the K8s Service to ensure endpoints within the same zone are used by kube-proxy while routing requests.(Reference)
Bonus
Aside from saving costs, limiting Inter-AZ data transfer offers two additional advantages as a bonus:
- Improving latency of requests between 2 services by keeping the traffic within a zone
- Increasing the system’s resilience in the event of an Availability Zone failure
References
- New traffic distribution feature
- EndpointSlice Controller throwing error
- PR for the Traffic Routing Preference
- Overload concept in TopologyAwareRouting